

用来衡量数据对称程度的指标
偏度-skewness(3次方)
峰度-kurtosis
why stdev cannot used for measure 数据对称程度? because stdev 是取了平方再根号,无法知道往哪一个方向偏离了中心
kurtosis--主要衡量异常值偏离均值的概率
和钱相关的基本都是右偏的
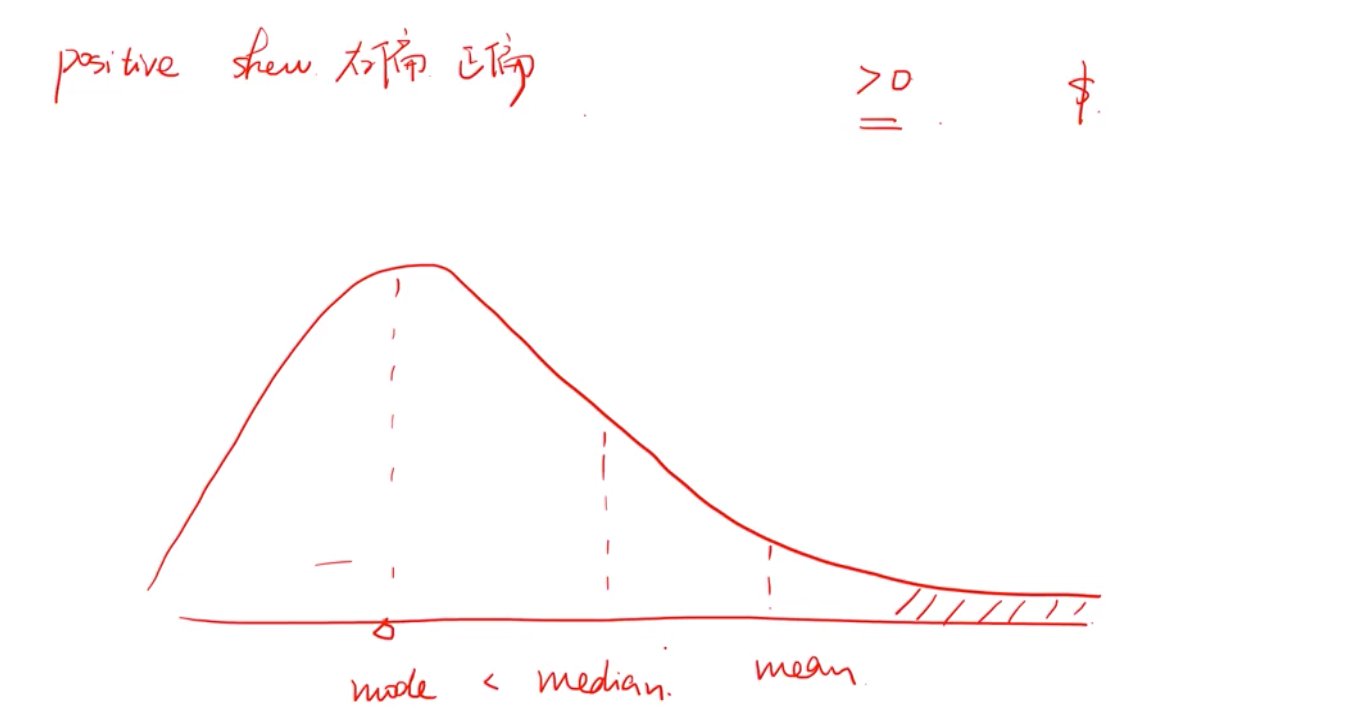
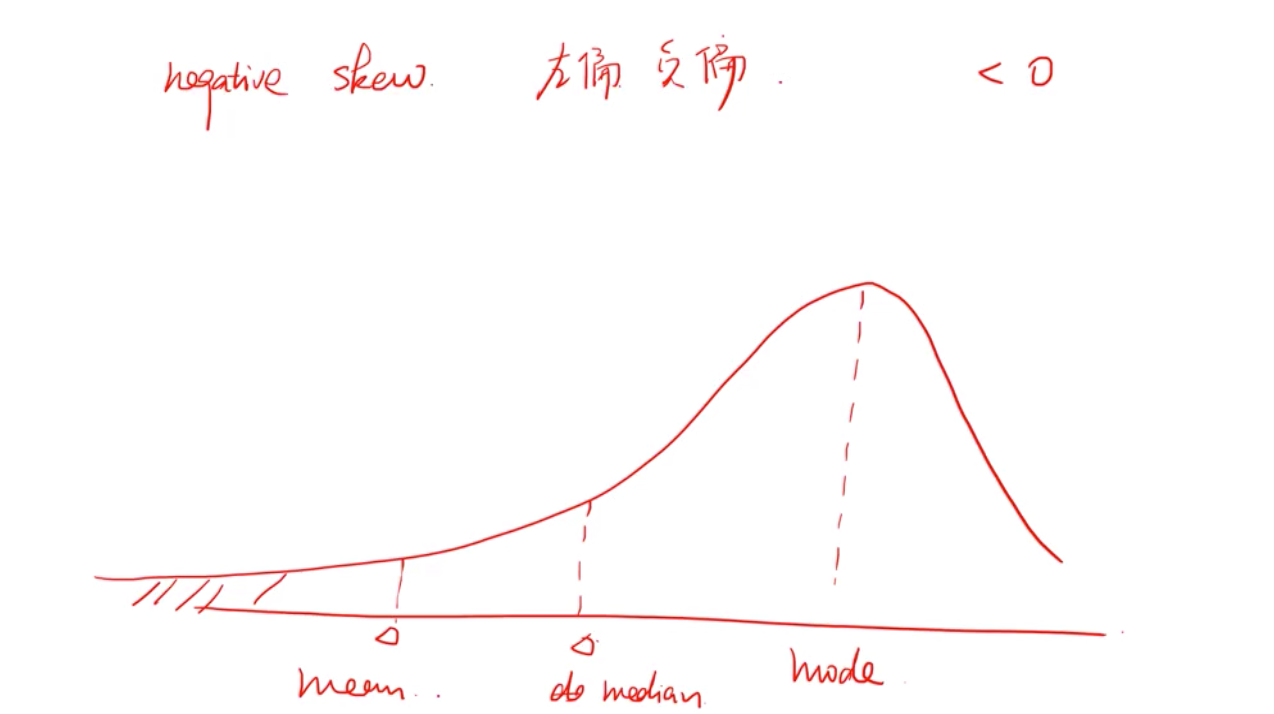
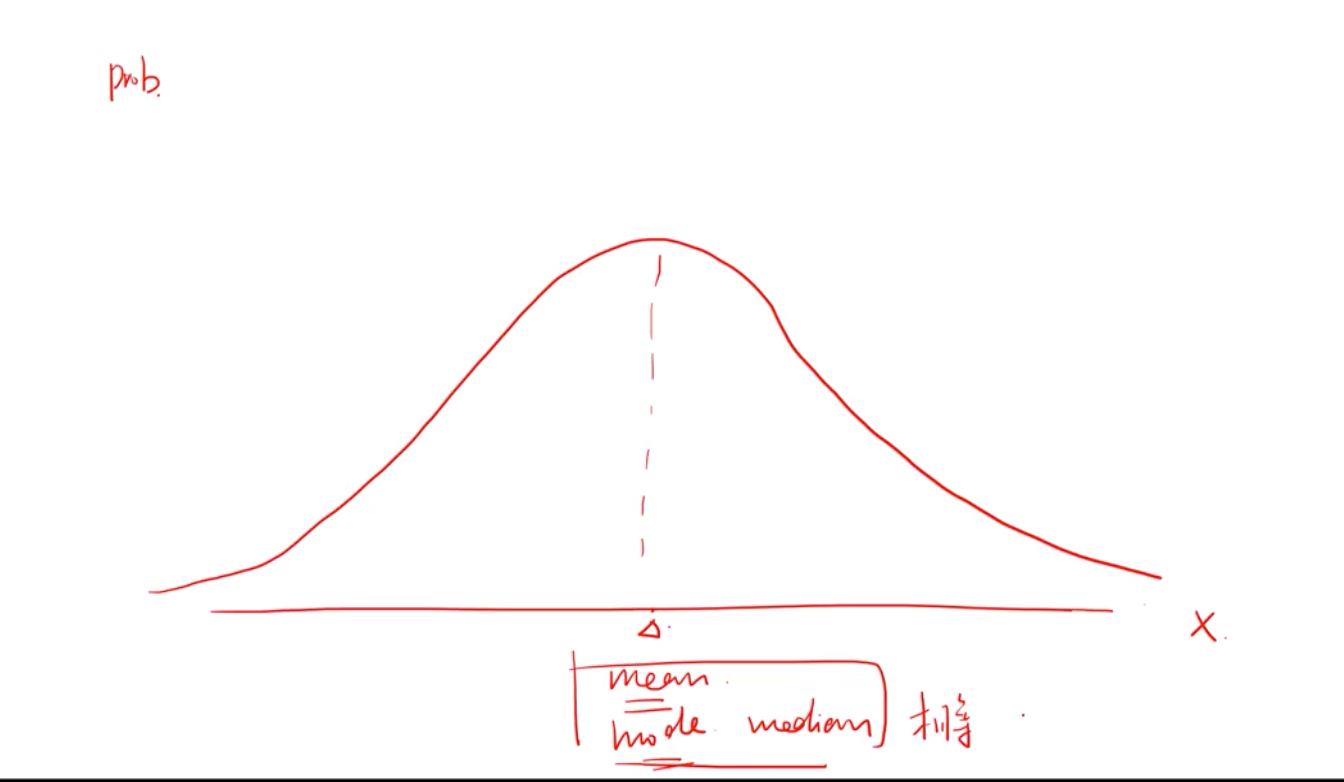
正态分布的峰度位3 --黑线

我们研究峰度是为了研究异常值, 高峰肥尾(蓝线)表示更高的频率出现极大的差异值, 低峰瘦尾(红线) 这个结论有一个隐含前提条件:即这组分布和正态分布一样,它的mode, mean, middle 是一样的






























































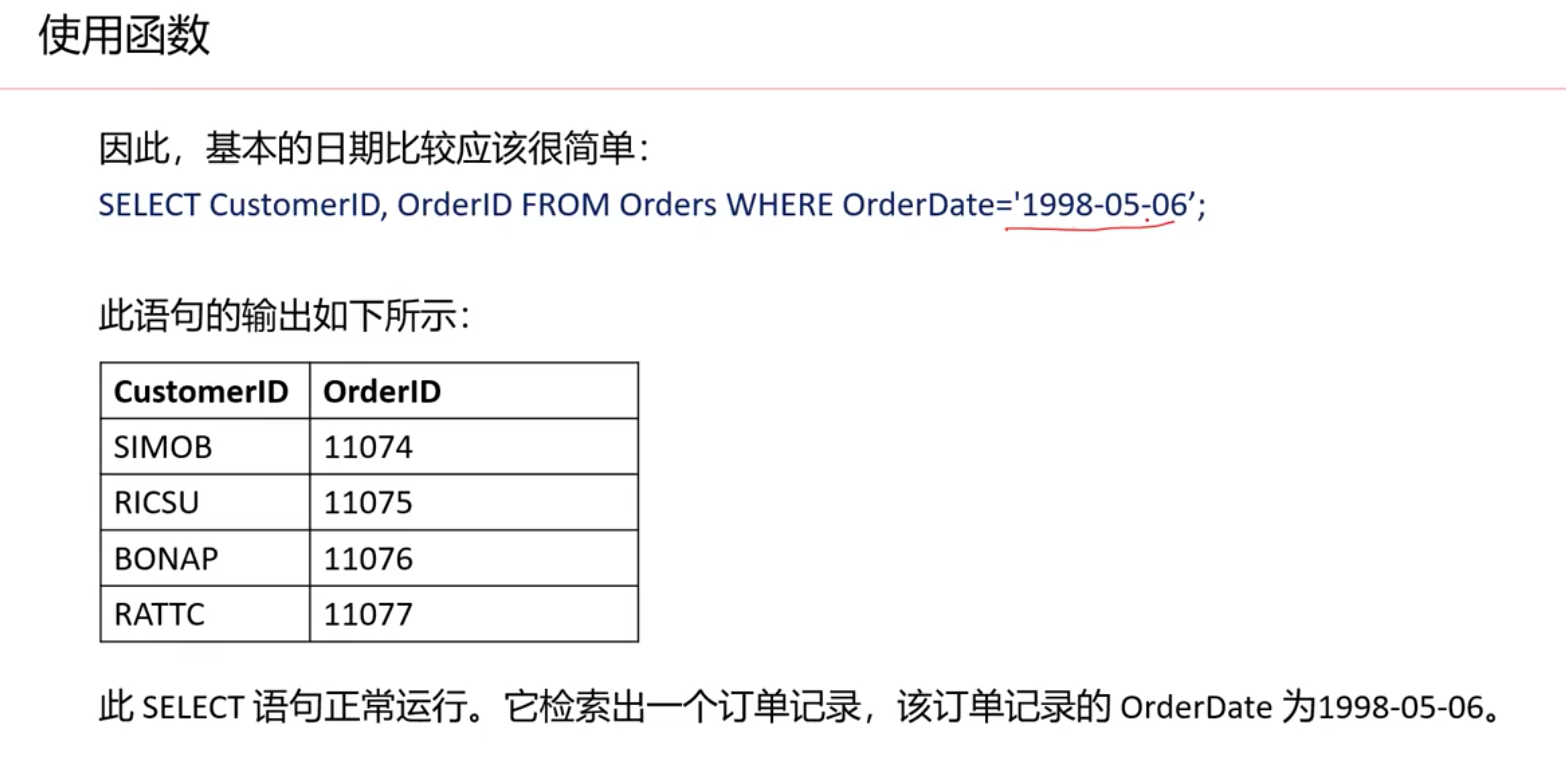










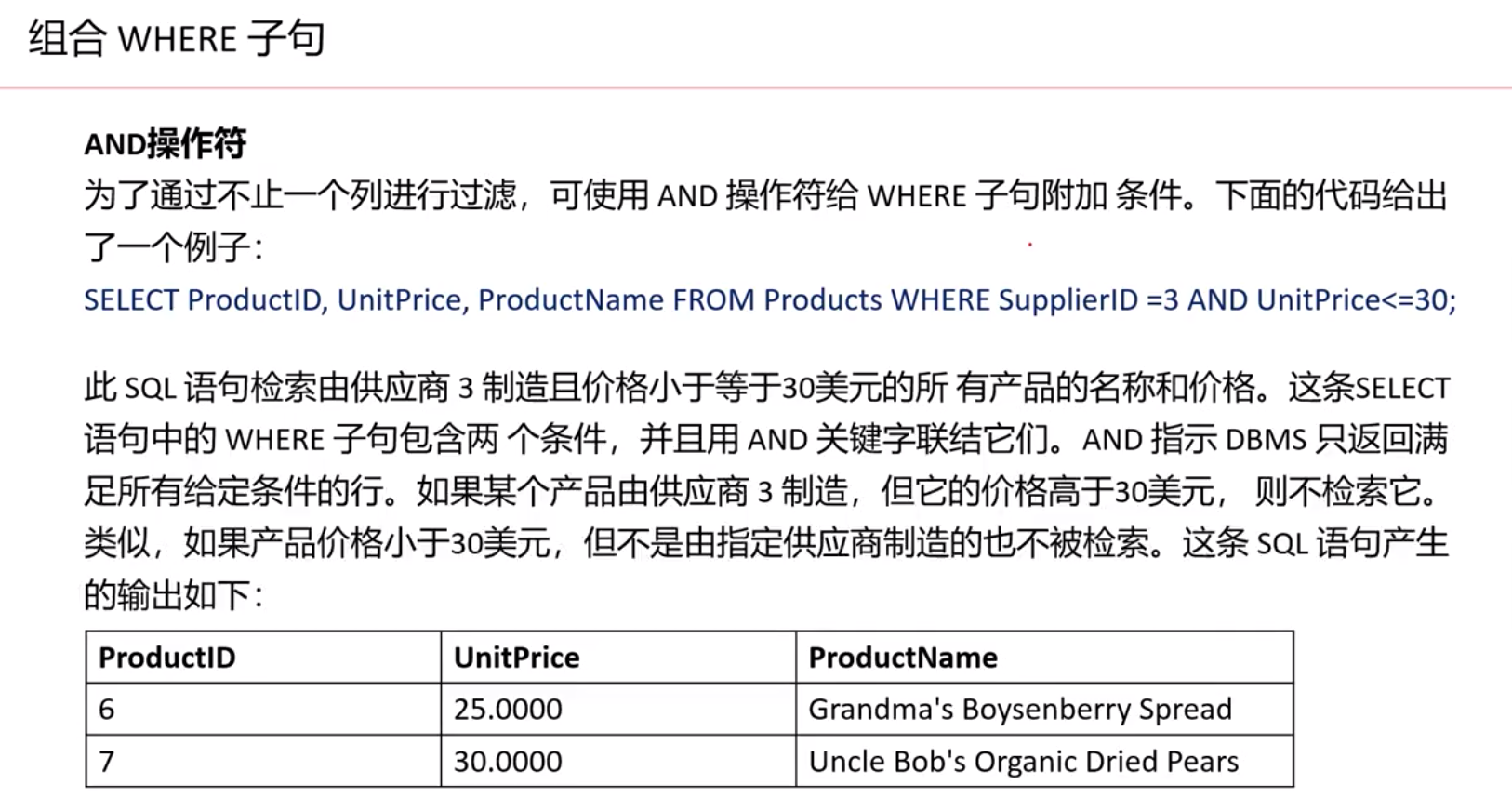





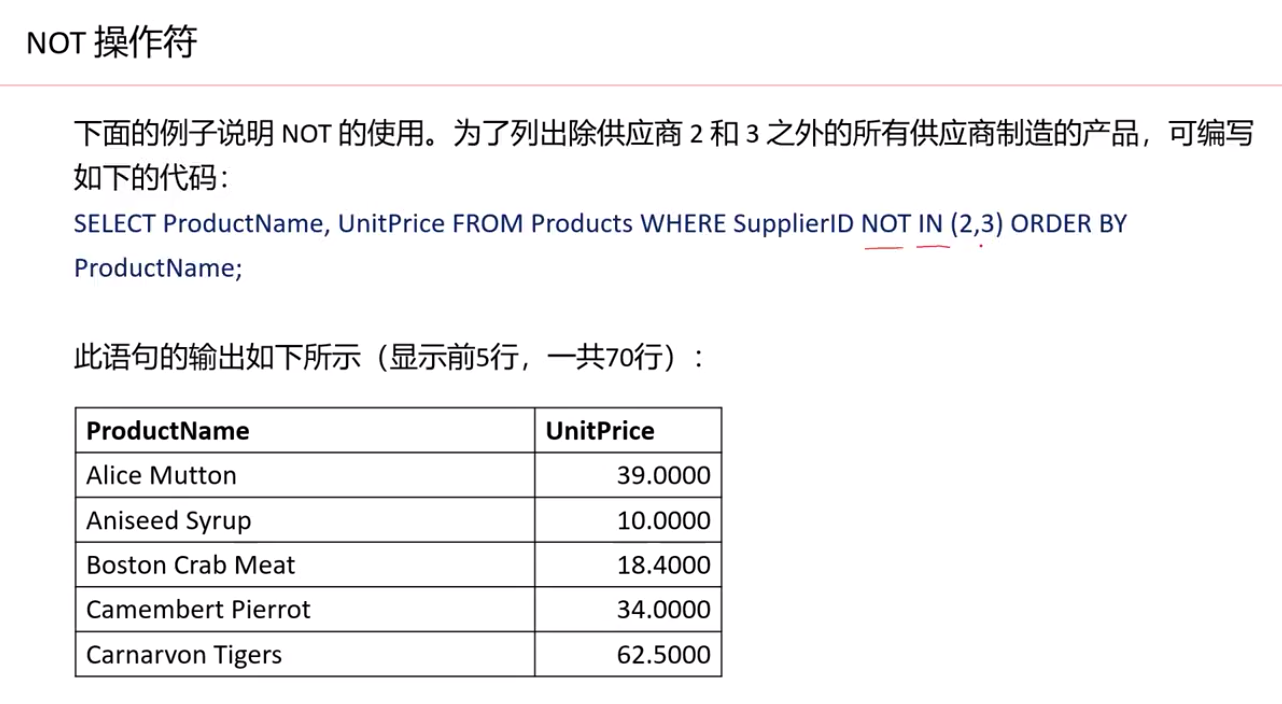

 使用where子句来过滤显示某些条件的记录
使用where子句来过滤显示某些条件的记录
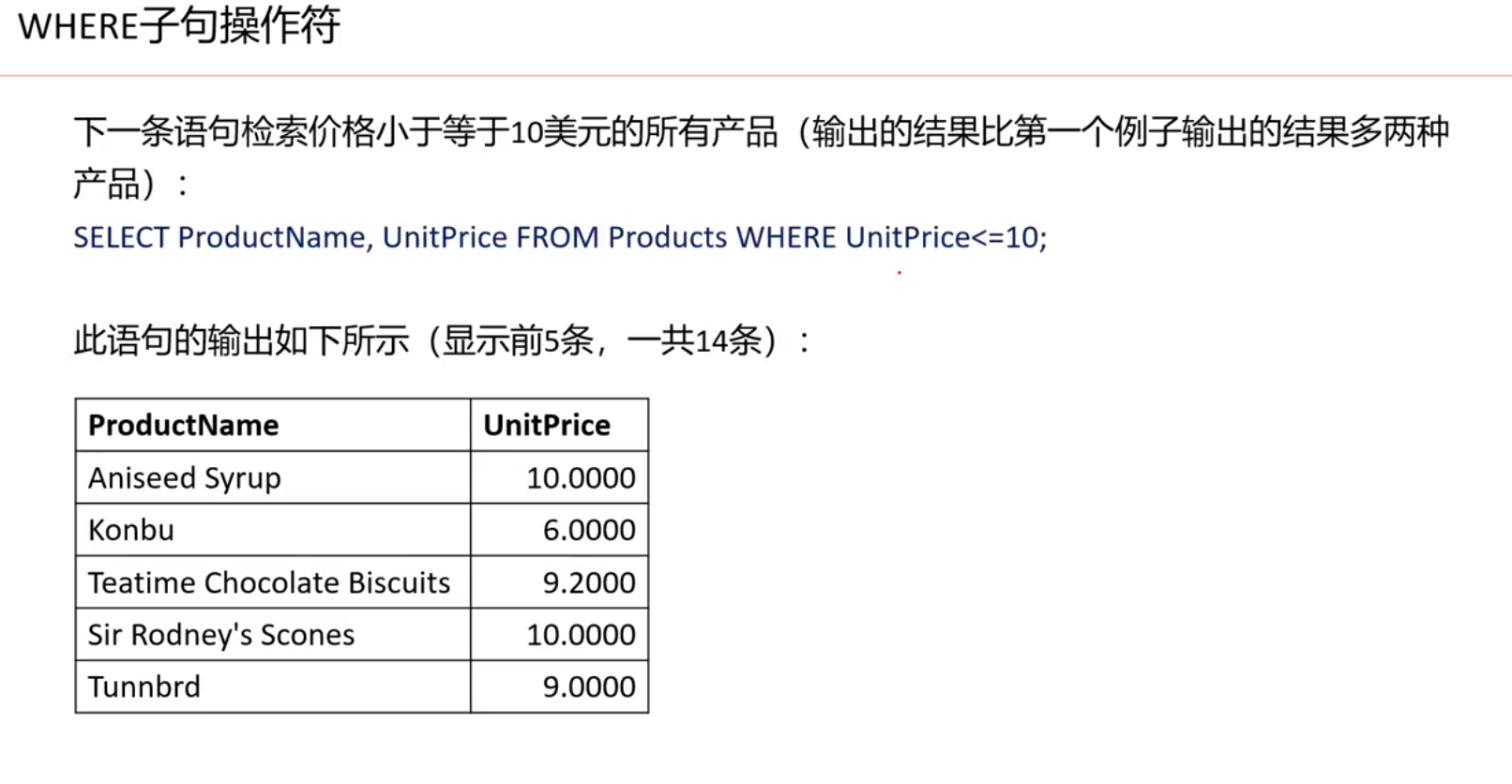













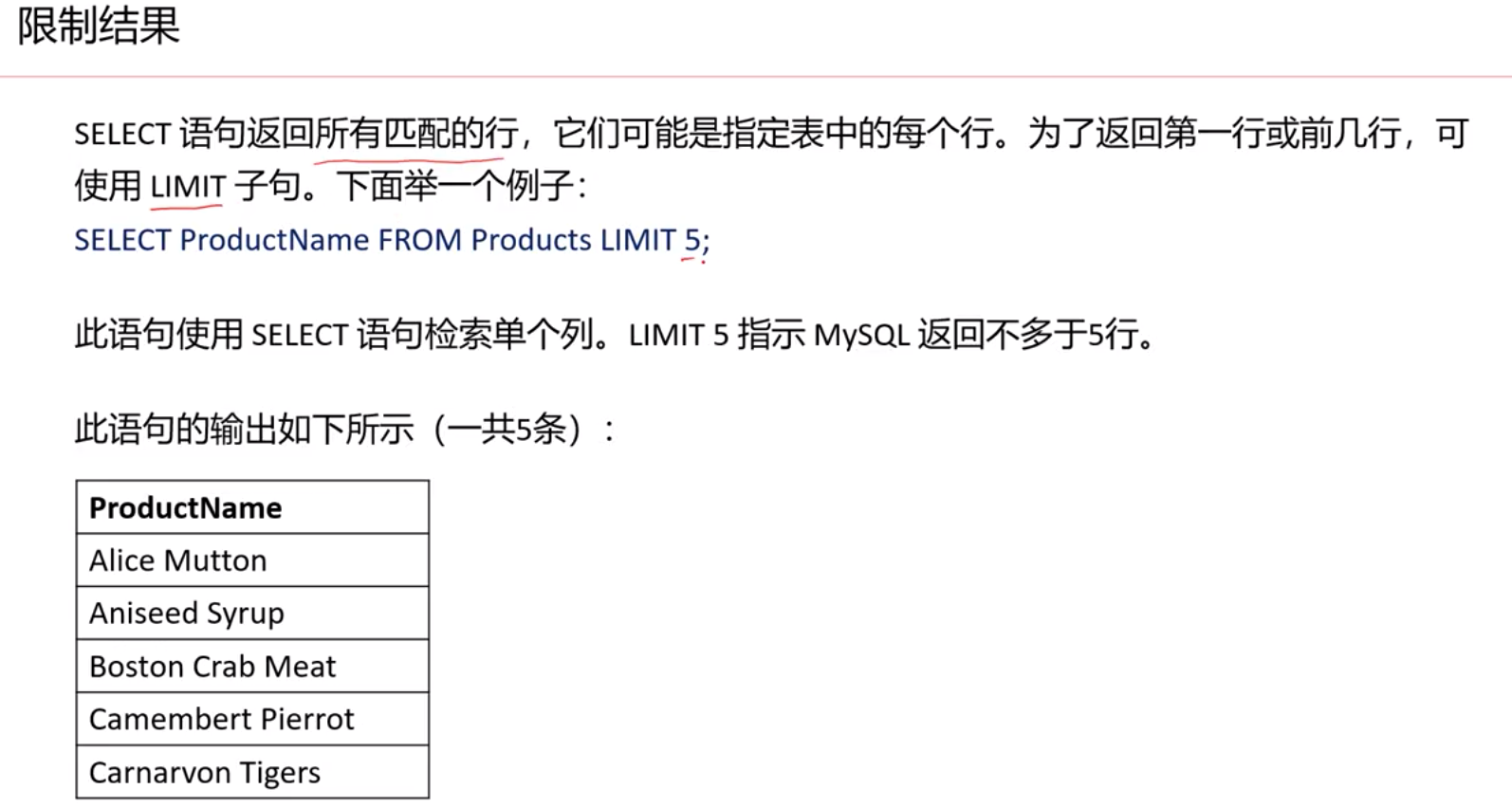
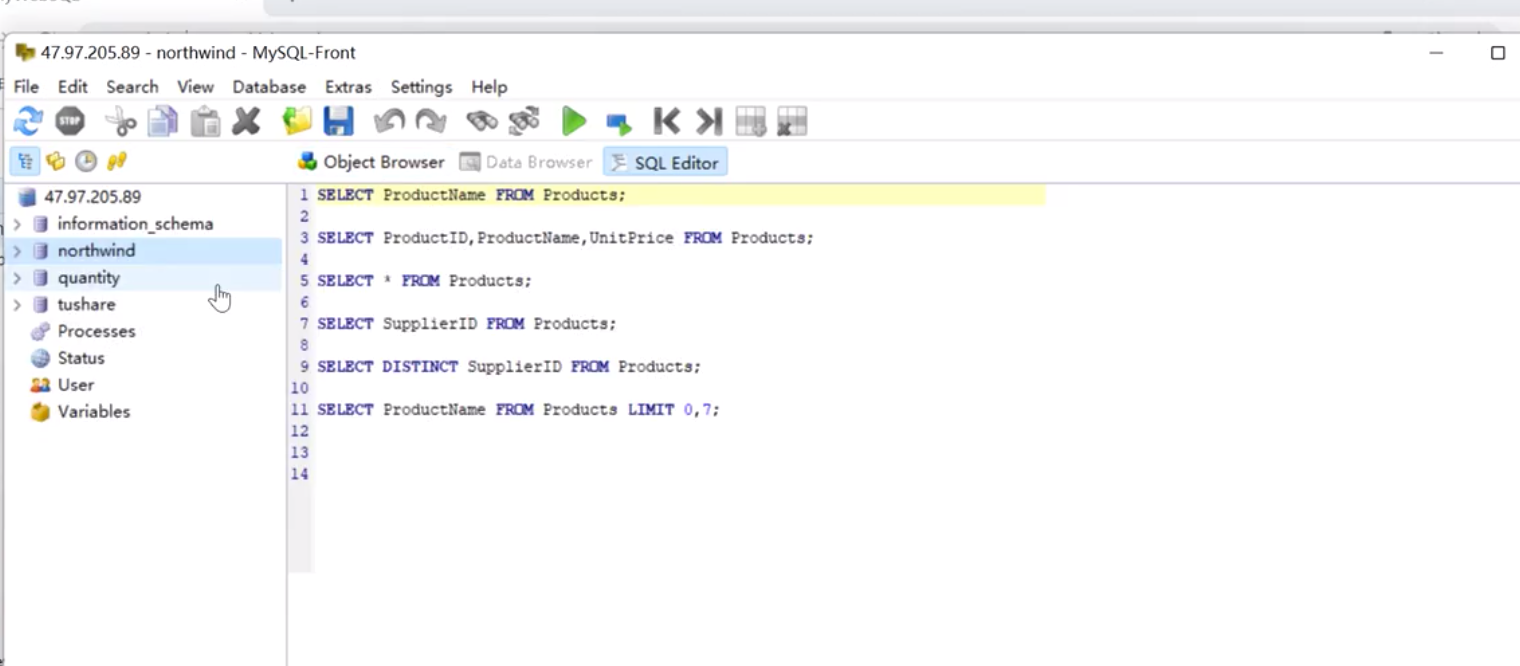
 检索多列字段名用半角逗号隔开。举例如下
检索多列字段名用半角逗号隔开。举例如下



















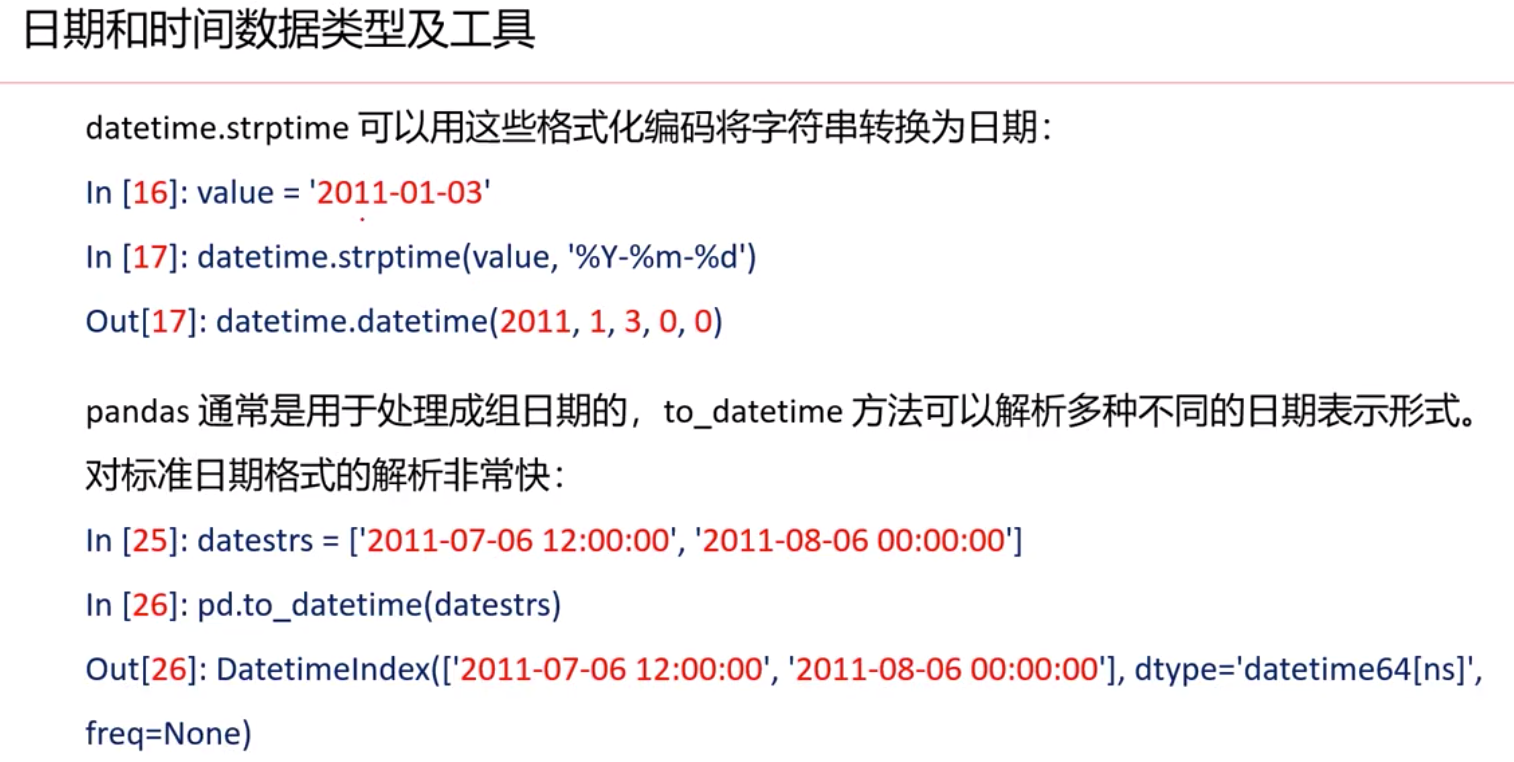
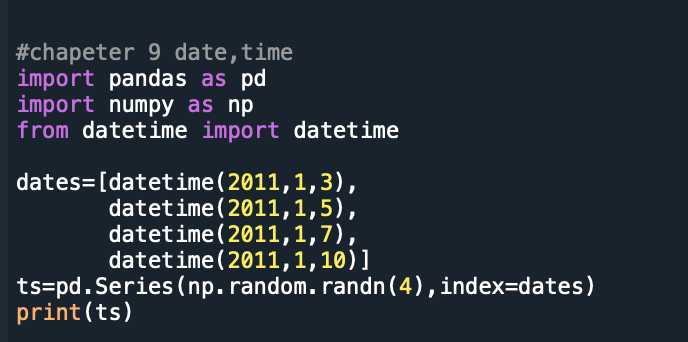
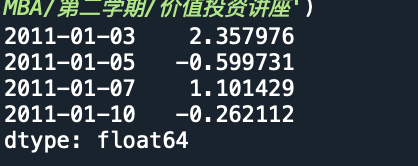



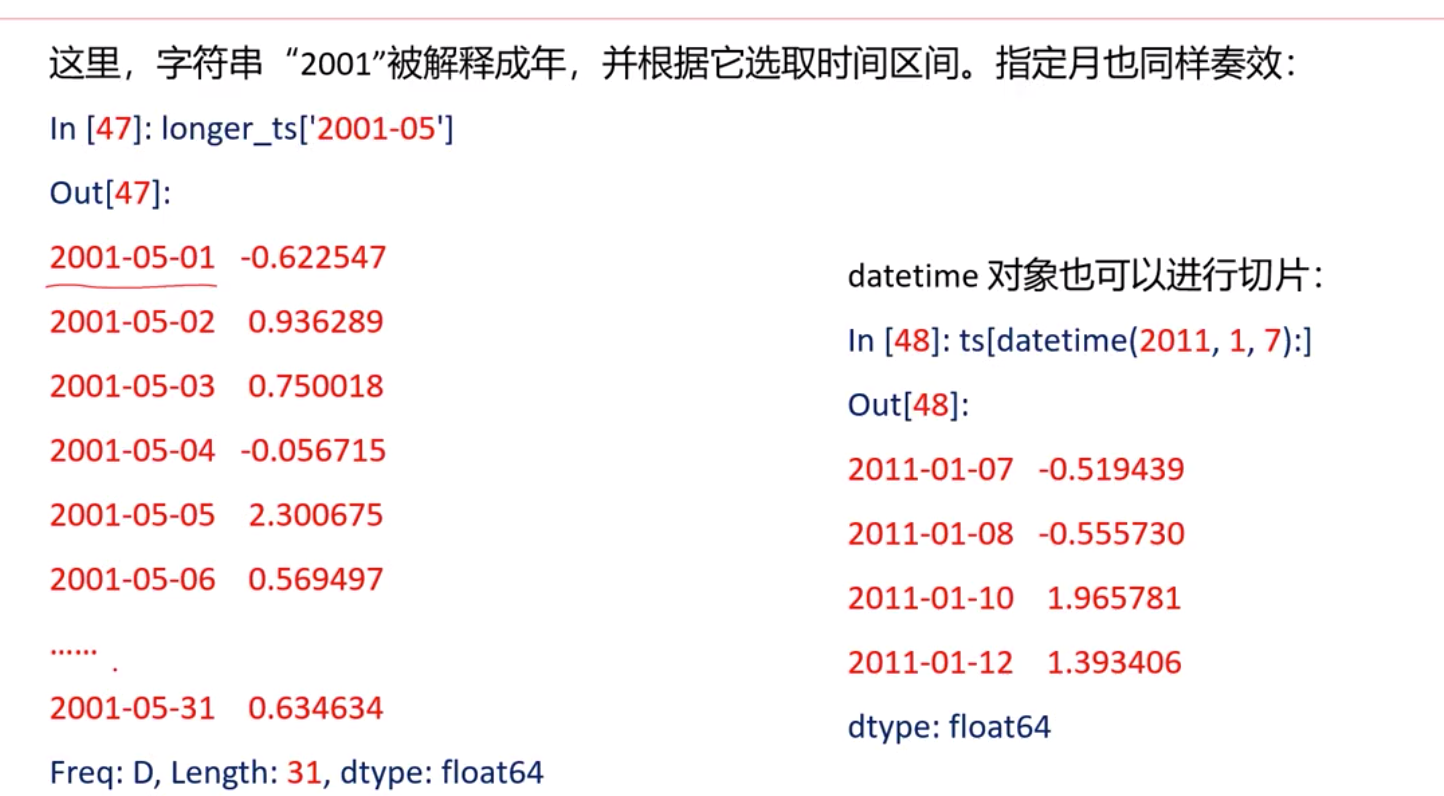





 同比,环比 用shift(2) shift(-2) 往前移动
同比,环比 用shift(2) shift(-2) 往前移动



