报错:invalid syntax 无效的句法
除法,获得浮点数
取证运算符 //
例如:3//2 得到: 1
或者,用int(3/2) 得到: 1
驼峰命名法
回车用: \n
count方法有点,s3字符串里有多少个换行
字符串就像羊肉串,将字符串起来。-字符串之后就不能改里面的某一个字符。
s4【10】是表示处理第11个。
.count是方法,必须有对象,字符串才有这个统计方法。
.replace也是方法,必须有对象
str函数转化为字符串
type是函数,不是方法,前面没有点的。
Key:切片操作(非常重要)
- unicode 统一码
- list函数将字符串转成列表-把羊肉串拆成一块一块。
- s[:3]表示0-第3个。-截取字符,容易出错。
- 口诀:五种变形,三种负数。
- a和b都是正数时,a+1,b不变。
- 变形:[:b] [a:] [a:b] [:] [x]
- a和b是负数,a不变,b-1。
- 特殊字符分转义和不转义:\ r‘’-r表示raw。
- 逗号分隔--用split拆分
- []表示列表
- 双冒号分隔符--用join是一种方法,必须是一个列表或元组
- 定位:
- in 左边是否在右边里面
- index find (?)-与视频结果不一致
- 练习!
key :模块化/格式化--format-字符串格式化是个很深的主题
- f:浮点
- s:字符串
- d:整数
切片总结: 自我总结,不知可否推广?
int float bool str


















 """
"""














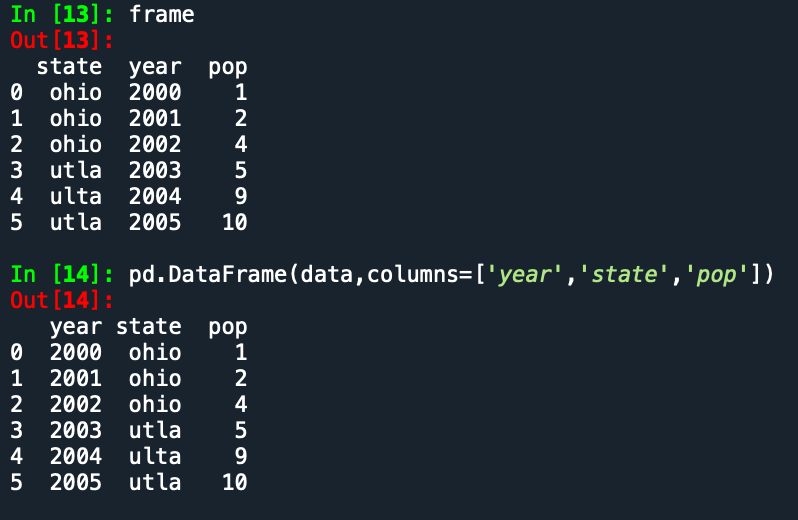

 要想获取dataframe的一个列,可以用点 也可以用【‘列名’】
要想获取dataframe的一个列,可以用点 也可以用【‘列名’】
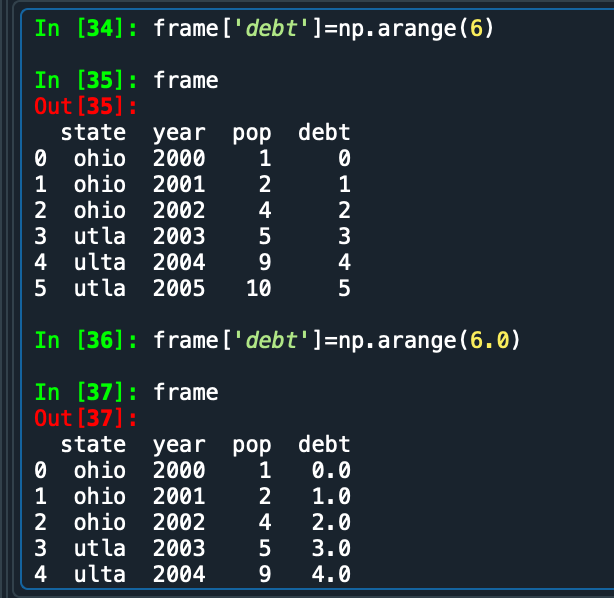



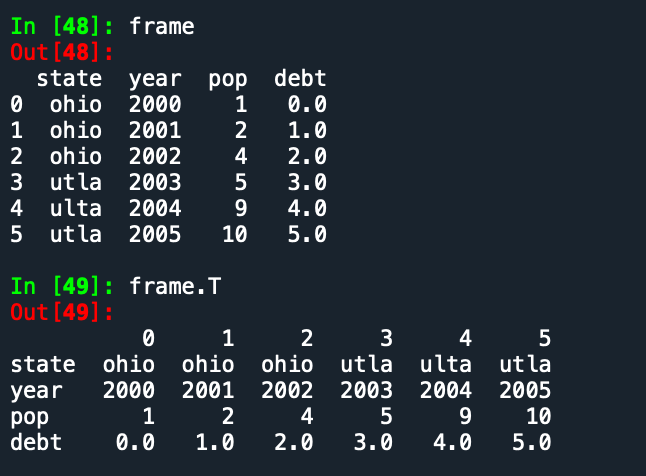



 iloc =indexlocation, data.iloc[2<第3 行>,[3,0,1<第4,第1,第2 列>] 实际位置是该数字+1, 如2 代表第2+1行。
iloc =indexlocation, data.iloc[2<第3 行>,[3,0,1<第4,第1,第2 列>] 实际位置是该数字+1, 如2 代表第2+1行。



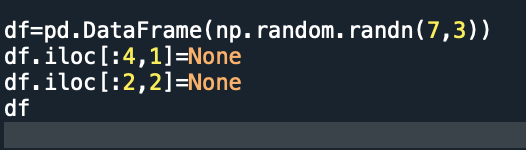
 skipna=false空值排除掉,不参与tong
skipna=false空值排除掉,不参与tong

 NumPy
NumPy





 标量即常数的意思
标量即常数的意思




 此例子中arr_slice[1] =12345 # 将前一个切片的第二个位置有12345 来替换掉。
此例子中arr_slice[1] =12345 # 将前一个切片的第二个位置有12345 来替换掉。

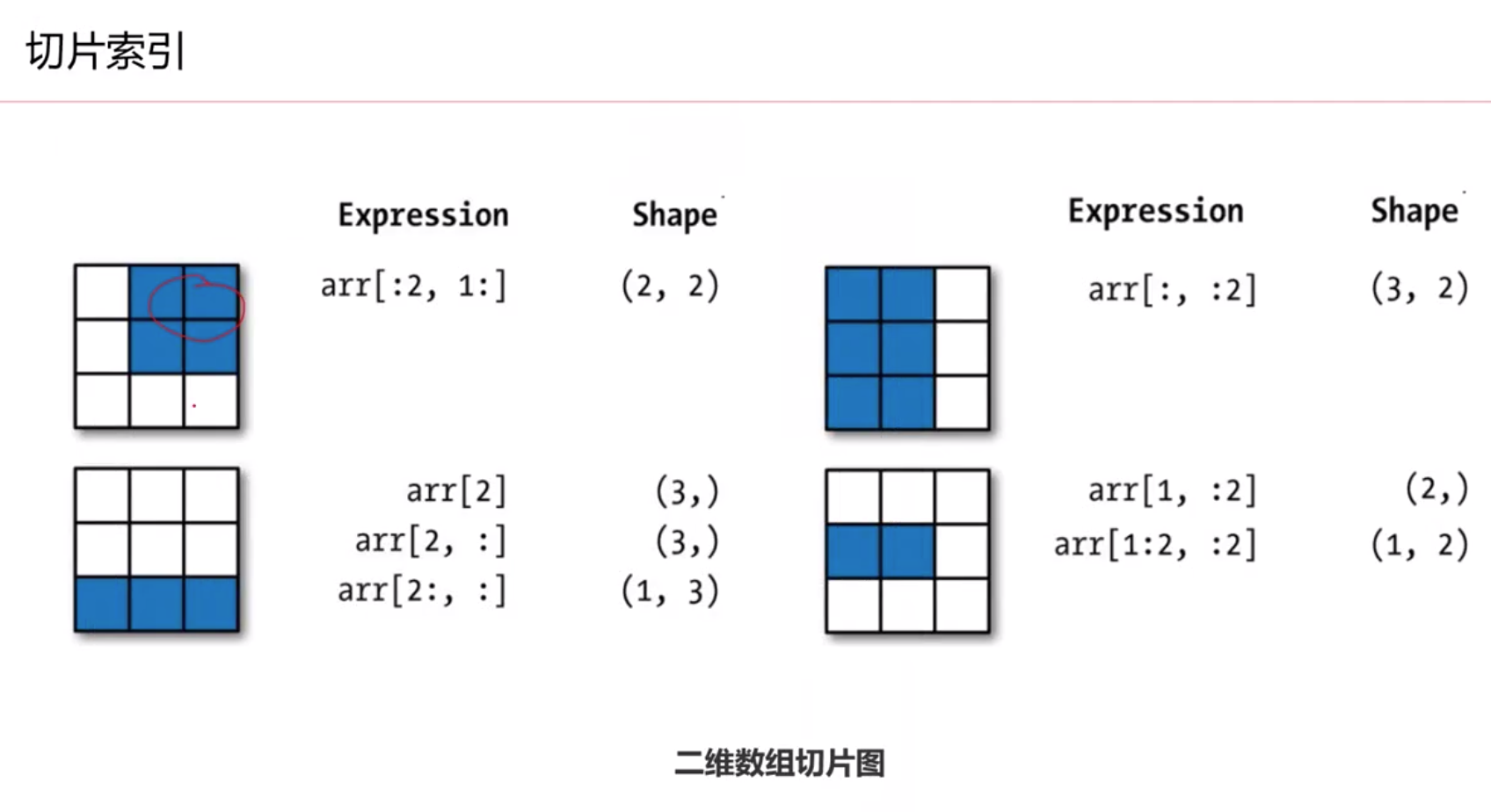
 给切片赋值(上图)
给切片赋值(上图)



























 pass 是占位语句。
pass 是占位语句。